
Combinations of Humans and AI - Research Paper Analysis - M. Vaccaro, A. Almaatouq, T. Malone (2024)
Most Human-AI teams are slower and worse than a good model. This deep analysis of a 2024 human-AI collaboration meta-study shows when humans+AI actually win, and how to design workflows that outperform both.
https://arxiv.org/abs/2405.06087
If you read tech Twitter, you’d think the answer is obvious.
Put a human and an AI together and you get a centaur:
human judgment + machine speed = strictly better results.
Every product is now a “copilot”.
Every process slide has a “human in the loop” bubble somewhere at the end.
But that whole story is still mostly marketing.
Very few teams actually stop and ask the uncomfortable question:
Across real tasks, in real experiments, do human+AI teams consistently beat either humans or AIs on their own?
That’s the question this paper goes after.
Do “Centaur Teams” Actually Work?
“Human in the loop” has become a safety blanket.
When leaders feel nervous about automation, they add a human step at the end of the pipeline: “the AI drafts, the human reviews”.
It sounds responsible. It signals control. But it quietly assumes something very strong: “If I add a human on top of an AI, performance can only go up.”
In practice, we’ve all seen the opposite:
- The AI is right, the human overrules it out of distrust.
- The AI is wrong, the human rubber-stamps it out of laziness or anchoring.
- The AI is good enough, but forcing a human to re-check everything just adds latency and cost.
So you end up with two agents looking at the same problem, but no real division of labor.
The human-AI pair is slower than the AI and sloppier than the best human.
You’ve added friction, not intelligence.
The “centaur” metaphor hides this. It suggests a seamless hybrid creature, when most real systems are more like a horse dragging a person who can’t decide when to pull the reins.
If we want to design serious human-AI workflows, we need data, not metaphors.
That’s where this paper comes in. Instead of running yet another isolated lab study, the authors step back and ask:
- What happens if we aggregate all the controlled experiments where humans and AI systems work together on a task?
- On average, do human-AI teams outperform humans?
- Do they outperform AI alone?
- Under what conditions do we see true synergy (the combo beats the best solo agent) vs pure drag?
They collect over a hundred experiments across domains (medicine, text classification, content creation, forecasting, image tasks, etc.) and run a proper meta-analysis.
The result is a quantitative map of where human-AI collaboration helps, where it hurts, and which design choices actually matter.
For builders and operators, this matters a lot more than yet another “AI strategy” keynote:
- If you’re wiring copilots into your product, this tells you which kinds of tasks benefit from human-AI teams and which should probably be handed fully to the model.
- If you’re designing internal workflows, it gives you evidence on when a “human review” step is real quality control vs a feel-good bottleneck.
- If, like me, you’re trying to build systems where humans and AI workers run business processes together, it gives you a baseline world model: what usually happens when you just plug a human next to an AI without thinking too hard.
The Research Question: When Are “Humans + AI” Better Than Either Alone?
At the highest level, the paper asks a deceptively simple question:
If you put a human and an AI together on the same task, do you actually get a better system than either one alone?
Not “does AI help humans a bit” and not “is AI impressive on this benchmark,” but the stronger statement: is the combined system strictly better than the best solo agent you have available?
To answer that, the authors first have to be precise about what counts as human-AI collaboration and what doesn’t.
Most people call anything that involves ChatGPT or a model “human-AI collaboration”. In this paper, that’s not enough.
They draw a line between:
-
Simple AI tool use:
the human uses an AI somewhere in the workflow, but the outcome is effectively credited to one side. Examples:- A doctor reads an AI-generated report but makes the final call alone.
- A marketer uses an LLM to brainstorm ideas, then discards most of them and writes the copy alone.
- A developer uses code suggestions but is evaluated purely on the final code quality.
In these cases, the AI is a tool the human deploys, like a better search engine or IDE. The evaluation is still “human performance with better tools,” not “human+AI as a distinct system”.
-
Human-AI collaboration (in this study’s sense):
both human and AI contributions are integral to the final decision or artefact, and you can meaningfully compare:- human alone,
- AI alone,
- and human+AI as a joint decision-maker.
Examples that qualify:
- The AI proposes a diagnosis, the doctor can adjust or override it, and the combined decision is what’s scored.
- The AI flags which images are suspicious, the human reviews only those, and the combined pipeline’s accuracy/efficiency is measured.
- The AI drafts a document, the human edits, and the quality of the final text is compared to human-only and AI-only versions.
The key point:
human+AI must be its own agent in the experiment, with its own measurable performance.
That matters for operators because it’s very close to how we design workflows:
- Is the AI just another internal tool that upgrades a human role?
- Or are you actually designing a joint system where control and responsibility are distributed between human and AI components?
This paper is only about the latter. It asks whether these joint systems are worth the complexity at all.
Once “human-AI collaboration” is pinned down, the authors frame three concrete comparisons:
- Human+AI vs Human alone
- Does adding AI assistance make humans better at the task?
- This is the “augmentation” perspective: are we giving people superpowers?
- Human+AI vs AI alone
- Given a competent AI, does involving humans still add value?
- Or are we just slowing down an already strong model?
- Human+AI vs the best of Human or AI
-
This is the real synergy question:
Does the combination beat the best solo performer you have?
-
If not, there is no true “centaur advantage”; you should just route the task to whichever solo agent is stronger.
-
For each published experiment they can find that fits their criteria, they extract:
- a performance metric (accuracy, F1, quality rating, etc.) for:
- human-only,
- AI-only,
- and human+AI;
- context about the task (decision vs creative, domain, difficulty);
- context about the AI (classic model vs LLM, year, training data era);
- details of the interaction design (AI suggests / human approves, voting schemes, escalation rules, etc.).
They then translate performance differences into a standard effect size (Hedges’ g), which lets them pool results across very different tasks, and run a three-level random-effects meta-analysis:
- Level 1: random noise in individual measurements,
- Level 2: differences between tasks inside a study,
- Level 3: differences between studies.
The question becomes:
- If I take all the places people tried human+AI teams in the wild, and I average out the noise, what do I see?
- On which kinds of tasks, and under which designs, does the joint system outperform the solo baselines?
- And in which cases is human+AI a net negative, more cost, more latency, less accuracy?
How the Meta-Analysis Was Done
Before we take the results seriously, it’s worth understanding what the authors actually did under the hood.
This isn’t “we ran a few tasks with GPT-4 in a lab”.
It’s a structured sweep across the whole landscape of human–AI experiments they could find.
Data Set
The authors start with a systematic search across major databases and venues, looking for controlled experiments where humans, AI systems, and human+AI combinations are all evaluated on the same task, with comparable metrics.
To make it into the dataset, a study needed to:
- Report performance for at least two of the three: humans alone, AI alone, human+AI together.
- Use a quantitative outcome (accuracy, F1, error rate, quality score, etc.) that can be normalized.
- Involve a real AI system, not just a toy random baseline.
- Clearly describe the interaction pattern.
After screening and filtering, they end up with:
- Over 100 distinct experiments (from dozens of papers).
- Hundreds of effect sizes (because one paper can include multiple tasks, conditions, or metrics).
The tasks span several domains, for example:
- Medical diagnosis / triage
- Document and image classification
- Content creation and editing
- Forecasting / prediction tasks
- Various decision-support scenarios
For each experiment, they reconstruct three key numbers wherever possible:
- Performance of humans alone
- Performance of AI alone
- Performance of the human+AI team
Plus metadata: task type (decision vs creation), domain, AI model type, year, and how the human and AI actually interacted.
This is what lets them ask the same questions across very different settings:
“On this task, is the combo better than human? Better than AI? Better than the best of the two?”
Measuring Performance
Different studies report different metrics: accuracy, error rate, area under the curve, Likert ratings, etc. To compare apples to apples, the authors translate these into a standardised effect size called Hedges’ g.
In simple terms:
- Think of Hedges’ g as “how many standard deviations better (or worse) condition A is than condition B.”
- means no difference.
- means A is about half a standard deviation better than B (a moderate effect).
- means a full standard deviation better (large effect).
- Negative values mean A is worse than B.
For example:
- If human+AI achieves 90% accuracy and humans alone achieve 80%, and variability is moderate, the effect size human+AI vs human will be a positive g.
- If AI alone is already at 92% and human+AI is at 88%, the human+AI vs AI effect will be negative.
They compute separate effect sizes for each comparison they care about:
- : human+AI vs human alone (augmentation effect)
- : human+AI vs AI alone (marginal human value)
- : human+AI vs best of human/AI (true synergy)
Each effect size comes with a standard error, which tells you how noisy that estimate is (small sample means noisier; large sample means more precise).
Once everything is translated into these g values, they can pool results across tasks and domains while still respecting how uncertain each estimate is.
Modelling Approach
Simply averaging all the g’s would be naïve.
Studies differ in:
- Sample sizes
- Task difficulty
- Domains and populations
- Interaction designs
- AI capabilities and vintages
To deal with this, the authors use a 3**-level random-effects meta-analysis:**
- Level 1 : Within-effect noise
- Random sampling error for each effect size (the usual statistical noise).
- Level 2 : Within-study variation
- Many papers report multiple tasks or conditions.
- These effect sizes are correlated (same participants, same AI system, same setting).
- Level 2 captures this extra clustering.
- Level 3 : Between-study heterogeneity
- Different studies use different domains, user populations, model types, and years.
- Level 3 captures that broader variation.
Why this matters:
- A fixed-effects model would pretend every study is estimating the same underlying true effect. That’s clearly wrong: human+AI on radiology is not the same thing as human+AI on marketing copy.
- A random-effects model assumes there’s a distribution of true effects, and each study samples from it.
The 3-level version goes further: it recognizes that effect sizes inside a study are more similar to each other than to effect sizes from other studies, and corrects the math accordingly.
They also compute heterogeneity statistics (like ) to show how much of the total variation is due to real differences between tasks/studies vs sampling noise.
Unsurprisingly, heterogeneity is high: human+AI performance varies a lot across contexts, which is exactly why we need moderator analyses (task type, relative human vs AI strength, interaction design) later in the paper.
The key takeaway is:
- The authors don’t cherry-pick a few favorite examples.
- They treat human-AI collaboration as a population of experiments,
- normalize them into a common metric,
- and then ask: “Across this whole population, what patterns consistently show up?”
That’s what gives their conclusions enough weight to use as a starting point for designing real human-AI workflows.
Big Picture Findings
Once you zoom out across all the experiments, three big comparisons matter:
- Does adding AI help humans?
- Does adding humans help a competent AI?
- Does the combination beat the best solo agent you have?
The short version:
- Yes to #1 (augmentation works).
- Meh on #2 (humans don’t add much to a strong AI).
- Mostly no on #3 (true synergy is rare).
Let’s unpack that.
Human+AI vs Human Alone
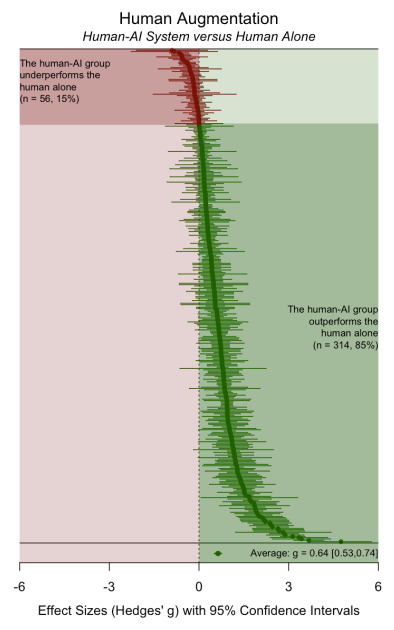
The cleanest result in the whole paper is this:
On average, human+AI teams significantly outperform humans working alone.
Across tasks and domains, when you give people a reasonably capable AI assistant and treat the human+AI pair as the decision-maker, performance goes up relative to human-only baselines.
In Hedges’ g terms, the average effect is solidly positive and statistically robust:
humans with AI help are meaningfully better than humans without it.
This is the part of the centaur story that is true:
- For doctors, models catch patterns they might miss.
- For analysts, models crunch data and surface candidates.
- For writers, models expand the search space of ideas and phrasings.
Even with all the design flaws in current systems, “AI as augmentation” works.
If your alternative is “humans alone,” you almost always win by adding a good model.
But that’s the low bar. The more interesting questions are what happens when you compare to AI alone, and to the better of the two solo agents.
Human+AI vs AI Alone
Things get more uncomfortable when you ask:
“Given a decent AI, does involving humans still add measurable value?”
Across all studies, the average difference between human+AI and AI alone is much smaller, often close to zero and sometimes negative.
In other words:
- If you start from “AI-only,”
- and then bolt humans on top in the usual ways (review, override, second opinion),
- you don’t consistently get better accuracy or quality.
You definitely get:
- higher latency,
- higher operational cost,
- and more organizational complexity.
But in pure performance terms, the evidence says:
humans don’t reliably improve on a strong AI baseline. They help in some contexts (we’ll see which later), and hurt in others, and it mostly washes out in the average.
This is a big deal:
- If your benchmark is “can we help humans with AI?”, you’ll feel good.
- If your benchmark is “can this mixed system actually beat a good model end-to-end?”, you’ll be disappointed most of the time.
This is the first place where “human-in-the-loop” stops being obviously virtuous and starts looking like a design choice you should justify.
Human+AI vs Best Agent (Human OR AI)
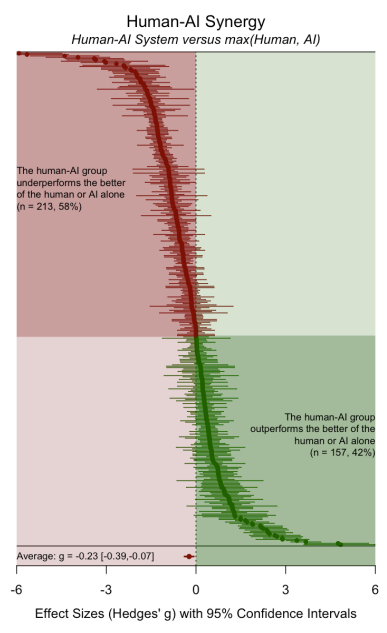
The real test of the centaur myth is the third comparison:
Does the combined human+AI system beat the best solo performer, whichever one that is?
Here, the headline result is blunt:
On average, human+AI systems underperform the better of human or AI alone.
The pooled effect size is negative.
If you simply route each task to the stronger agent (human OR AI), you usually do better than forcing them to collaborate.
Why does synergy fail so often?
The qualitative patterns across studies point to a few recurring issues:
-
Redundant work instead of division of labor:
Human and AI both look at everything. There’s no clear rule for who handles which cases, so you just add more eyes without adding more information.
-
Anchoring and over-reliance:
Humans get biased by AI suggestions. When the AI is wrong, people often follow it anyway.
-
Distrust and over-correction:
In other settings, humans systematically distrust the model and override correct suggestions, injecting their own errors.
-
Friction costs
Coordination, review and escalation steps add time and cognitive load. Even small decreases in accuracy can’t justify the extra overhead.
The meta-analysis makes one thing clear:
synergy is not the default outcome of putting a human next to an AI.
The default, on average, is slightly worse than just picking the stronger agent and letting it run.
That reframes the goal:
- Don’t start from “human+AI is obviously better”.
- Start from “human+AI is probably worse than the best solo agent unless we design the interaction very carefully.”
Conditions for Positive Human-AI Synergy
The meta-analysis is pretty harsh on naive “human-in-the-loop” setups.
But it also shows there are pockets where human+AI genuinely outperforms either alone.
3 ingredients show up again and again when the sign flips from negative to positive:
- The type of task (decision vs creation)
- Who is stronger to begin with (humans vs AI)
- How the workflow is actually wired (division of labor vs redundancy)
Let’s go through each.
Where Humans Add the Most Beyond AI
The first moderator the authors look at is task type. They roughly split tasks into:
- Decision / classification tasks : predicting labels, diagnoses, categories, outcomes.
- Creation / generative tasks : writing, editing, designing, brainstorming new artefacts.
Task type isn’t the whole story. The meta-analysis also looks at who’s stronger at baseline: do humans alone beat AI alone, or the other way around?
They find:
- When humans already outperform the AI, adding the AI is more likely to create positive synergy.
- The model plays a supporting role: surfacing options, catching edge cases, reducing mundane load.
- The human stays the primary decision-maker, with AI as leverage.
- When AI outperforms humans on the task, adding humans tends to hurt more often than it helps.
- Humans overrule correct model outputs.
- Or they add little value but consume attention and time.
- The combo system drifts towards “AI performance minus human friction.”
In other words:
You get the best human+AI systems when you start from a strong human and add AI,
not when you start from a strong AI and bolt humans on for cosmetic “safety”.
This is slightly counter-intuitive because in practice we often say:
- “Put humans in the loop where AI is weakest.”
But the evidence is closer to:
- Use AI where humans are weak,
- Use humans+AI where humans are strong and AI gives leverage,
- Avoid forcing humans to “improve” a model that’s already better than them on that dimension.
For your own system design, this is a good rule of thumb:
- First, benchmark humans vs AI on the task.
- Then decide whether you want:
-
AI-only,
-
human+AI with human in the lead, or
-
human-only,
based on who actually has the edge.
-
The pattern is stark:
- On decision tasks, human+AI often does worse than a strong AI alone.
- These tasks tend to be well-defined, with clear right/wrong answers.
- A modern model can be extremely calibrated here.
- Adding humans mostly introduces noise (overrides, anchoring, second-guessing) and latency.
- On creation tasks, human+AI tends to outperform AI alone more consistently.
- Humans add taste, context, and non-obvious constraints (brand, politics, emotion).
- AI expands the search space of candidates and handles the heavy lifting.
- The result is closer to “human creativity with a turbocharger” than to “two agents voting on a binary decision”.
In other words:
If the task is “pick the right answer from a known set,” the model often shines on its own.
If the task is “create something new and useful,” humans still bring a lot to the table.
This suggests a default stance:
- Decision-heavy pipelines (classification, routing, triage, scoring):
start from AI-first, and only add humans at clear escalation points. - Creation-heavy pipelines (content, design, research synthesis):
design for tight human+AI loops, where the model proposes, the human shapes, and the model refines.
Synergy When Humans Outperform AI on the Task
Task type isn’t the whole story. The meta-analysis also looks at who’s stronger at baseline:
do humans alone beat AI alone, or the other way around?
They find:
- When humans already outperform the AI, adding the AI is more likely to create positive synergy.
- The model plays a supporting role: surfacing options, catching edge cases, reducing mundane load.
- The human stays the primary decision-maker, with AI as leverage.
- When AI outperforms humans on the task, adding humans tends to hurt more often than it helps.
- Humans overrule correct model outputs.
- Or they add little value but consume attention and time.
- The combo system drifts towards “AI performance minus human friction.”
In other words:
You get the best human+AI systems when you start from a strong human and add AI, not when you start from a strong AI and bolt humans on for cosmetic “safety”.
This is slightly counter-intuitive because in practice we often say:
“Put humans in the loop where AI is weakest.”
But the evidence is closer to:
- Use AI where humans are weak,
- Use humans+AI where humans are strong and AI gives leverage,
- Avoid forcing humans to “improve” a model that’s already better than them on that dimension.
This is a good rule of thumb:
- First, benchmark humans vs AI on the task.
- Then decide whether you want: AI-only, human+AI with human in the lead, or human-only, based on who actually has the edge.
Interaction Patterns and Division of Labor
The third ingredient is how humans and AI interact.
Across the studies, most workflows fall into a few crude patterns:
- AI suggests, human decides: The model outputs a recommendation. The human either accepts or overrides it.
- Human decides, AI flags: The human does the task. The model flags potential errors or unusual cases.
- Voting / averaging schemes: Human and AI outputs are combined mechanically (e.g., majority vote).
What’s mostly missing is designed division of labor. Rules like:
- “AI handles all low-uncertainty cases; only high-uncertainty cases go to humans.”
- “AI drafts; humans only edit sections where confidence is below X.”
- “AI proposes top-3; humans choose among them only when these conditions hold.”
The few studies that do implement something like this (dynamic triage, selective escalation, calibrated confidence thresholds) show more promising signs of synergy, even if the sample is still small.
This lines up with a basic systems principle:
You don’t get emergent intelligence from stacking agents. You get it from clear contracts about who does what, when, and based on which signals.
- You can choose whether the human or AI goes first.
- You can choose what information each sees.
- You can define precise escalation rules and feedback loops.
The meta-analysis is telling you that this is the lever that moves you out of the “synergy usually fails” regime:
- Put humans on the parts of the task where they genuinely have an edge.
- Let the AI own the rest end-to-end.
- Minimize redundant checks.
- And let data, not vibes, decide when and where to escalate.
When Human-AI Systems Hurt Performance
So far we’ve looked at when human+AI can work.
But the meta-analysis is very clear on something most teams don’t like to admit:
A lot of current human-AI systems make things worse.
Not worse than “humans with no tools”, worse than just letting the better solo agent (often the AI) run the task end-to-end.
The same patterns of failure show up across domains: humans overriding correct AI, naive review steps that add friction, and a blind belief that “more eyes = more intelligence.”
Let’s break those down.
Trust, Bias, and Anchoring Effects
One of the most common failure modes the paper surfaces is humans systematically overriding correct AI outputs.
It usually looks like this:
- The AI makes a prediction or suggestion.
- The human sees it, but either: doesn’t trust the model (“this looks wrong, I’ll go with my gut”), or feels the need to “add value” by changing something.
- In many of these cases, the AI was right and the human change is wrong.
Across multiple experiments, you see:
- Under-trust : experts are reluctant to accept model outputs, especially in high-status domains (medicine, law, etc.).
- Over-correction : humans feel pressure to “do something,” so they edit even when they don’t have strong evidence.
- Weird calibration : users either lean too heavily on the AI or ignore it, instead of using it as probabilistic input.
The flip side also shows up: anchoring.
Once the AI suggests something, humans tend to stick close to it even when they should override:
- If the model’s first guess is off, human reviewers drift towards that error.
- Even experts can get pulled away from their correct initial instincts by seeing the AI suggestion.
Both under-trust and over-trust produce the same effect:
The human+AI pair is worse than the AI alone on that task.
The meta-analysis doesn’t claim humans are irrational. It points out that we haven’t given them:
- good calibration training (when to trust vs override),
- transparent confidence signals from the AI, or
- clear accountability rules (who is responsible if they accept or reject the AI’s output).
In the absence of that, people act like humans: biased, social, and loss-averse. And they drag down the system.
Latency and Cognitive Load from Naive Human-in-the-Loop Design
The second big way human-AI systems hurt performance is more boring but just as real: friction.
Most “human in the loop” designs in the studies look like this:
- AI does the task.
- Human re-checks everything.
- Final answer comes from that combined process.
On paper, this sounds safer. In practice, it introduces:
- Latency : everything takes longer, even easy, high-confidence cases the AI would have nailed instantly.
- Cognitive load : humans must read and think about every case, even when their marginal contribution is near zero.
- Attention dilution : instead of focusing on ambiguous, high-value edge cases, the human’s attention is smeared across the entire stream.
The meta-analysis is focused on accuracy/quality, not cost or speed, but some studies explicitly report:
- No significant gain in accuracy versus AI-only,
- With an obvious increase in time and effort from the human side.
If you’re running an ops-heavy business, that’s a disaster:
- You’ve tied up your most expensive resource (people)
- In a loop that doesn’t actually improve outcomes
- While slowing down the entire pipeline.
The problem is simple:
You’re treating the human as a general-purpose patch instead of a specialist resource.
Instead of asking “for which 10-20% of cases is human review actually worth it?”, the design says “just send everything to a human at the end.”
The result is predictable: burnout, slower cycles, and no real performance gain.
Why “More Eyes on the Problem” doesn’t mean More Intelligence
Behind both of these failure modes is a comforting but wrong intuition:
“If we put more eyes on a decision, it must get better.”
The meta-analysis shows that at system level, that’s just not true.
Human+AI often underperforms the best solo agent because:
- Redundancy without structure: Human and AI both look at the same cases with no clear rule for who does what. You pay twice and gain nothing.
- Error correlation: Humans inherit AI biases via anchoring, and AIs can amplify human label noise they were trained on. Two agents can be wrong in the same direction.
- Noise > signal: When humans add low-quality overrides or edits, they’re injecting noise into a decision that was already good enough.
More components in a system can reduce reliability when:
- the components aren’t independent,
- there’s no principled aggregation rule, and
- you’re not measuring the combined output against a clear ground truth.
The meta-analysis is essentially a giant empirical rebuttal to the vague “centaur” story:
- More agents ≠ more intelligence.
- More steps ≠ more safety.
- More humans ≠ more quality.
What improves intelligence is design:
- Who sees what, and when.
- How disagreements are resolved.
- Which parts of the space are delegated to which agent.
- How feedback loops update both human practice and model training.
If you don’t design those pieces, the default outcome of adding “human in the loop” is exactly what this paper finds on average:
A system that is slower, more expensive, and slightly worse than just picking your best agent and letting it run.
Design Principles for High-Performance Human-AI Workflows
The meta-analysis doesn’t just say “centaur myths are overrated.”
Between the lines, it gives us a design brief:
If you want human+AI systems that actually win, you have to architect them.
Here are 4 principles you can use as a checklist when you design workflows, products, or internal ops.
Put Humans Where They’re Strongest, Not Everywhere
The studies are clear: human+AI synergy shows up when humans outperform AI on some important dimension of the task, and the workflow lets them express that advantage.
That usually means:
- Ambiguous cases
- Novel situations
- Ethical trade-offs
- Tasks where context, taste, or tacit knowledge matter
And synergy is weakest (or negative) when:
- Tasks are narrow classification problems
- The model is already better-calibrated than the median human
- Humans are bolted on “for safety” without any extra information or authority
So instead of “human in every loop,” design for:
- AI-only where:
- The task is well-defined,
- The model is objectively stronger than typical humans,
- The cost of occasional error is acceptable or can be mitigated upstream.
- Human+AI where:
- Humans have an edge (judgment, domain nuance),
- The AI can expand options, speed up exploration, or handle volume.
- Human-only where:
- The task is too under-specified for current models,
- Or the cost of delegating is not worth the risk (e.g., certain legal or political decisions).
Defaulting to “humans everywhere” wastes your scarcest resource.
Defaulting to “AI everywhere” ignores the few places where humans really increase system capability.
Clear Rules for AI Autonomy and Human Escalation
Most failed setups in the studies have one thing in common: no real division of labor.
Human and AI both touch everything, and the aggregation is vague (“human has final say”).
The few promising ones do something different: they partition the problem.
Examples of partition rules:
- By confidence
- AI handles all cases where its calibrated confidence is above a threshold.
- Anything below that threshold is automatically escalated to humans.
- Humans spend time only on “hard” cases.
- By type
- AI does detection / retrieval / first-pass filtering.
- Humans do synthesis, explanation, negotiation, exception handling.
- By stage
- AI drafts; humans set constraints and accept/reject whole blocks.
- Humans design policy; AI executes within that policy.
The pattern:
You don’t want a soup of human and AI touches.
You want a routing function that decides who owns what.
Concretely, for each workflow:
- Define when the AI is fully autonomous.
- Define what conditions trigger human involvement.
- Define what information each side sees when they act.
- Define how feedback (human corrections) flows back into model updates.
If you can’t write these as explicit rules, you probably don’t have a system yet, you just have people staring at model outputs.
Minimize Friction Interactions and Measure the Whole System
The meta-analysis quietly punishes any design where humans are just tacked on at the end as universal reviewers: performance doesn’t improve, and cost/latency explode.
Good systems minimize friction interactions:
- Avoid sending every case to a human “just in case.”
- Avoid asking humans to re-judge things where they have no comparative advantage.
- Avoid designs where humans must mentally recompute the whole task instead of evaluating a focused question.
Instead, design interactions like an API:
- Ask humans narrow, high-leverage questions:
- “Is this above or below risk tolerance?”
- “Which of these 3 options matches policy best?”
- “Does this violate any constraint we haven’t encoded yet?”
- Make sure humans have:
- The right context,
- The right controls,
- And a clear definition of done.
Crucially: measure the whole system, not just individual components.
Instrument:
- Quality (accuracy / error rates / ratings)
- Latency (end-to-end, not just model response time)
- Human effort (time-on-task, cognitive load, error rates)
- Rework loops (how often humans override, how often overrides are right)
Then ask:
- Is human+AI actually better than AI-only on the metrics that matter?
- If not, where exactly is the friction, and can we remove that interaction entirely?
Without measurement, “human in the loop” is just a comfort story you tell yourself.
Designing Human-AI Systems for Operations
Most current products stop at “copilot”:
- A box where you type,
- A suggestion that appears,
- A vague sense that “AI is helping.”
The meta-analysis makes it clear that this level of design is not enough if you care about system-level performance.
For operations the real design unit isn’t the copilot, it’s the process:
- Who owns which step?
- What’s the handoff?
- What’s automated, what’s conditional, what’s human-only?
- How do decisions compound over time?
Moving from copilots to processes means:
- Treating the model as a worker with a defined job, not a magic box.
- Treating humans as specialists invoked under specific conditions, not general-purpose patchers.
- Building feedback loops where corrections and outcomes retrain both humans (through playbooks) and AI (through data).
If you think in your usual language:
- The human-AI workflow is an agentic system with an objective, constraints, and a world model.
- The design principles above are how you specify its policy.
The lesson from this paper is not “humans+AI don’t work.”
It’s:
Naively combining humans and AI usually fails. Deliberately designed human-AI systems can outperform both.
Your job as a founder or operator is not to “add AI” or “add a human in the loop”. It’s to design the full-stack loop.
Research Gaps
This meta-analysis is probably the best snapshot we currently have of human-AI collaboration in the wild.
But like every serious paper, it’s honest about what it doesn’t cover.
Those omissions are not bugs; they’re the frontier.
Most of the experiments in the dataset look like this:
- A well-defined task
- A fixed model
- A fixed group of users
- A short time window (one session or a few rounds)
You measure: who’s more accurate today (humans, AI, or human+AI)?
What’s missing is the time dimension:
- How do humans change after weeks or months of working with AI?
- How does the AI change when it continually ingests human corrections and edge cases?
- How does the division of labor evolve as both sides learn?
Real organizations don’t run static one-shot experiments. They run learning loops:
- Policies get updated.
- Models get retrained.
- People develop intuitions about when to trust or ignore the system.
- Edge cases become new “normal” cases over time.
The meta-analysis can’t tell us:
- Whether a workflow that looks suboptimal on day 1 evolves into a superior system by day 100.
- How quickly humans calibrate to AI strengths and weaknesses in a live environment.
- What happens when you deliberately design training curricula for humans and models in tandem.
So one big research gap is simply:
longitudinal human-AI systems.
The paper gives us a static picture; operators need a dynamic one.
Another limitation: the unit of analysis here is almost always an individual human plus an AI system on a micro-task.
But in real companies:
- Work is done by teams, not isolated individuals.
- Tokens of collaboration include:
- Who owns the metric,
- Who gets blamed for errors,
- Who is rewarded for speed vs caution,
- Who can override whom.
The experiments generally don’t model:
- Incentives
- Is the human punished for trusting the AI and being wrong, or for being slow?
- Are they rewarded for catching AI errors, or for throughput?
- Power structures
- Does the human feel they must correct the AI to prove value?
- Or that they must never contradict it to avoid friction?
- Team-level coordination
- Multiple humans + multiple models working on shared queues.
- Handoffs between roles (ops, legal, finance), each with their own tools.
All of these shape how humans interact with AI in practice.
You can wire the perfect decision rule on paper and still get bad outcomes if incentives push people to override, ignore, or game the system.
The meta-analysis surfaces systematic effects (overriding, anchoring, friction), but it doesn’t have the vocabulary to talk about culture, power, or incentives.
That’s a massive gap between academic setups and organizational reality.
If you zoom out, this paper is saying something very simple and very uncomfortable:
most human-AI systems we build today are badly wired.
Human+AI routinely beats humans alone, but almost never beats the best solo agent unless you’re intentional about where humans sit, how work is partitioned, and what the system is actually optimized for.
That’s the shift I care about. Not “add a copilot” or “put a human in the loop,” but treat every workflow as an engineered human-AI system with an explicit objective, clear division of labor, and real measurement.
The meta-analysis gives us the priors; the rest is on us.